Minimal. Offline. Local.
A single binary CI system that runs on your laptop — no infra, no cloud, no configuration files.
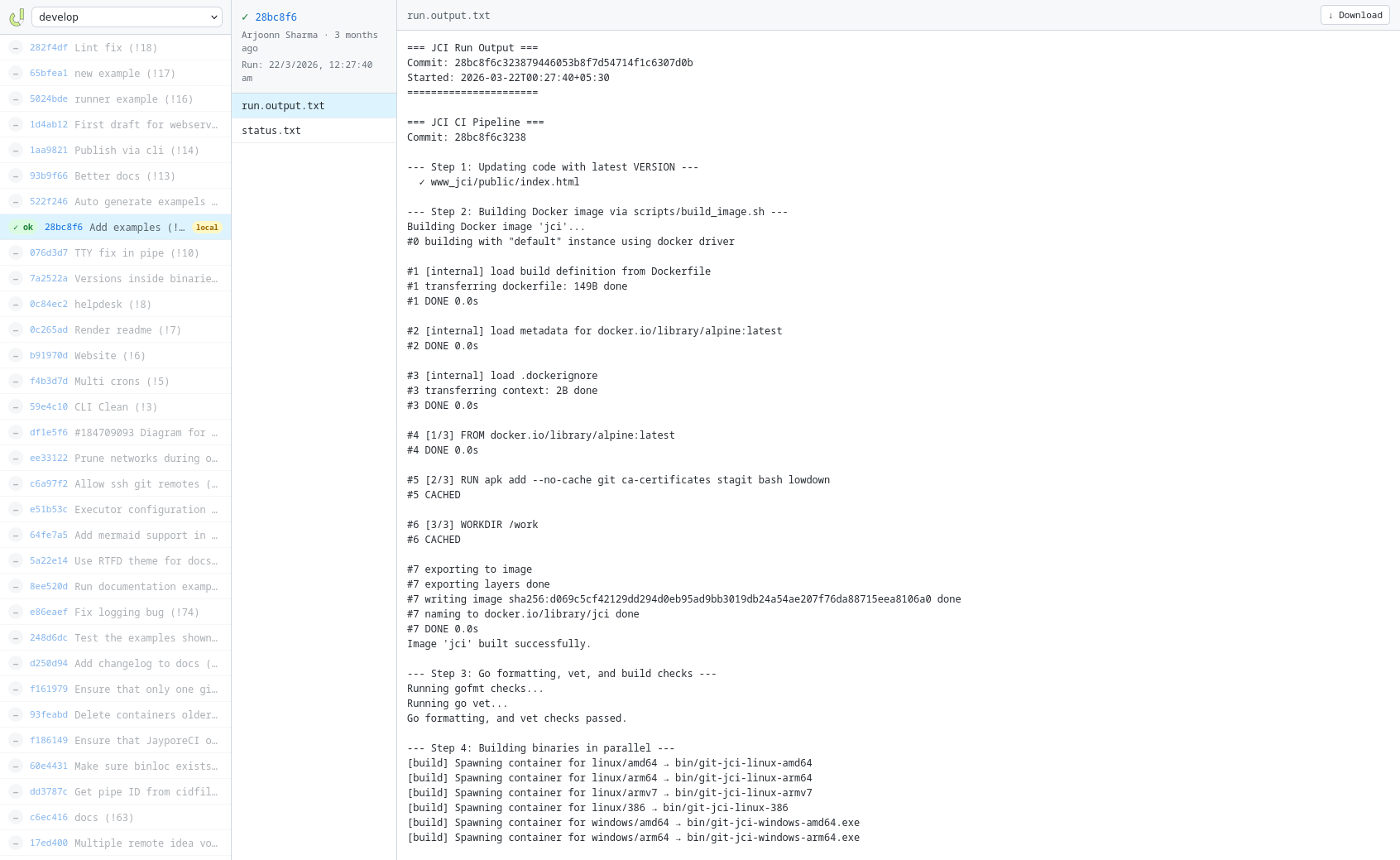
git jci web dashboard — browse CI results locally in your browser.Everything you need. Nothing you don't.
Single binary
Drop git-jci on your PATH. Git picks it up as a subcommand. No daemons, no agents.
Works offline
CI runs on your laptop without internet access. Results stay inside the git repo as regular objects.
Your pipeline, your rules
.jci/run.sh is any executable you like — shell, Python, a Docker call, anything.
Docker isolation
Run jobs inside containers via the distributed server + runner mode. Fully pull-based; no open ports on runners.
Cron scheduling
A .jci/crontab file becomes real system cron entries. Midnight builds, hourly scans, weekly reports.
Git-native sharing
CI results are stored under refs/jci-runs/* and sync with git jci push/pull — like any branch.
Local web UI
git jci web starts a dashboard at localhost — browse results, download artifacts, inspect logs.
No vendor lock-in
Works with any git remote (Gitea, GitHub, GitLab, bare servers). The CI data is yours, in your repo.
Up and running in one command
Paste this in your terminal — the script detects your OS and architecture automatically:
curl -sSL https://jayporeci.in/install.sh | shInstalls to ~/.local/bin/git-jci. Linux only. macOS: build from source with go build ./cmd/git-jci.
Or download a binary directly. After placing it on your $PATH:
mkdir -p .jci && cat > .jci/run.sh << 'EOF'
#!/usr/bin/env bash
set -euo pipefail
cd "$JCI_REPO_ROOT"
echo "Hello from Jaypore CI on commit $JCI_COMMIT"
EOF
chmod +x .jci/run.sh
git add -A && git commit -m "add CI"
git jci runThen open the results: git jci web
Binaries
Available for Linux (amd64, arm64, armv7, 386) and Windows (amd64, arm64). See the downloads page.
Real-world pipelines to get you started
Each example below is a working .jci/run.sh you can copy into your project.
Support Jaypore CI
This software is provided under the MIT License. If you use it for commercial purposes — within a company, for a client, or in a paid service — please consider purchasing a Commercial License. Your support keeps the project alive.
Talk to us on Help Desk or email support@midpathsoftware.com.